
Data management : les clés pour centraliser, sécuriser et exploiter vos données avec HubSpot
Une entreprise qui ne sait pas où sont stockées ses données clients et ne peut y accéder prend un risque de conformité dès le premier contrôle RGPD.
Une bonne gestion de données commence par des droits d’accès clairement définis et une méthode rigoureuse pour stocker, exploiter et sécuriser les informations.
Toutefois, à mesure que les volumes augmentent et que les applications se multiplient, s’appuyer sur une plateforme capable de centraliser et de fiabiliser les données devient un véritable levier de performance.
Des solutions comme HubSpot CRM, via son Data Hub et ses outils dédiés au data management, permettent justement de créer une source unique de vérité pour l’ensemble des équipes. 🚀
Data management : définition et principes fondamentaux
Derrière la gestion de données, la réalité n’est pas forcément la même selon le type d’entreprise.
Dans une PME ou une TPE, le sujet commence souvent par des questions très concrètes :
- Où sont stockées les données clients ?
- Qui peut y accéder ?
- Comment préserver leur confidentialité ?
Dans une structure plus importante, le data management s’appuie sur des règles, des outils, des responsables dédiés et plusieurs bases d’informations interconnectées.

Qu’est-ce que la gestion de données exactement ?
La gestion de données désigne l’ensemble des pratiques, des outils et des systèmes utilisés pour collecter, stocker, organiser, gérer, partager, puis supprimer les données, tout au long de leur cycle de vie.
On appelle data manager, ou gestionnaire de données, la personne qui veille à ce que les utilisateurs accèdent à la bonne information, au bon moment, sans compromettre la confidentialité. 👨💻
Ce qui change vraiment, c’est la logique de pilotage.
Il ne s’agit pas seulement d’administrer un système d’information, mais de considérer les données comme un actif de l’entreprise.
Une mauvaise gestion des données produit d’ailleurs des conséquences immédiates : erreurs de décision, difficultés de conformité, perte de confiance et exploitation limitée des informations sur les clients. 😬
Pour répondre à ces enjeux, certains outils intègrent désormais des fonctionnalités dédiées à la qualité des données.
Par exemple, le logiciel dédié à la qualité des données de la plateforme HubSpot aide à détecter automatiquement les doublons, à identifier les informations obsolètes ou à signaler les propriétés incomplètes susceptibles d’altérer la fiabilité des analyses. ✨
Quels types de données sont concernés ?
Les types de données à traiter ne se ressemblent ni par leur format ni par leur usage.
Voici les principales catégories d’informations rencontrées :
- Données structurées : elles sont organisées en lignes et colonnes dans des bases de données. Il peut s’agir des ventes, des stocks ou encore des fiches clients.
- Données semi-structurées : issues de formats comme XML ou JSON, elles proviennent souvent d’API, de flux web ou d’échanges entre applications, et nécessitent souvent un travail de transformation.
- Données non structurées : emails, images, vidéos, documents PDF… La plupart du temps nombreuses et dispersées, elles sont plus difficiles à exploiter dans une stratégie cohérente.
Avec le développement du big data… 🌐
…La collecte de données non structurées augmente rapidement.
La différence se joue alors sur la capacité de l’entreprise à mettre en place une vraie gouvernance, plutôt qu’à accumuler un grand nombre de fichiers sans méthode.
Dans cette perspective, des outils comme la synchronisation des données de HubSpot facilitent la coordination entre les différentes applications professionnelles. Les informations issues des logiciels commerciaux, marketing ou de support restent ainsi cohérentes, limitant les ressaisies et les écarts entre systèmes. 🔄
Pourquoi la donnée est-elle un actif stratégique ?
Une entreprise s’appuie sur ses données pour mieux décider, mieux servir ses utilisateurs, piloter son activité et exploiter ses informations clients. 💡
Pour l’analyse avancée, ce qui compte n’est pas seulement le volume : il faut des formats cohérents, des champs standardisés et des données exploitables d’un outil à l’autre.
Les utilisateurs et les partenaires s’attendent aussi à avoir des garanties concernant la collecte de données, leur usage et leur protection.
Il faut savoir par exemple qu’une notification de violation de données au titre du RGPD doit être adressée à la CNIL dans les 72 heures, délai que seule une gestion structurée est capable de tenir. ⏱️
Donc même si vous avez peu de contacts clients, il vaut mieux définir dès le départ qui accède aux données, sur quel outil, et pendant combien de temps. C’est ce paramétrage initial qui évitera à l’entreprise des problèmes coûteux à solutionner ultérieurement.
Pour aller plus loin…
Certaines solutions proposent également des fonctionnalités d’analyse avancée. Les datasets alimentés par l’IA de HubSpot, par exemple, permettent d’unifier les données déstructurées, au service d’une analyse plus efficace et d’une prise de décision éclairée. 🧠
Le 6 étapes cycle de vie des données
Le cycle de vie des données va de la collecte à la suppression : chaque étape influence directement la fiabilité, la sécurité et l’utilisation des data dans l’entreprise.
Il est important de prendre chaque phase en considération, car dans les faits, de nombreux problèmes apparaissent très tôt dans le cycle.
Et une erreur lors de la collecte peut rapidement se propager à l’ensemble du système : tableaux de bord erronés, analyses biaisées, décisions inadaptées…
De la collecte au stockage des données : les 3 premières étapes
La première moitié du cycle de vie des données repose sur un enchaînement simple : récupérer, structurer, puis conserver.
Si cette base est mal posée, la qualité des informations se dégrade rapidement, même lorsque l’entreprise dispose d’outils performants d’analyse ou de pilotage.
Les 3 premières phases de la gestion des données sont les suivantes :
- Collecte et ingestion : les données arrivent depuis différentes sources, comme un CRM, des capteurs IoT, des formulaires web, des partenaires ou des applications internes. Surveillez les formats et la manière dont les informations sont captées afin d’éviter les erreurs dès le départ.
- Intégration et organisation : les informations issues de systèmes hétérogènes sont regroupées, standardisées et structurées afin de maintenir la cohérence avec les processus de l’entreprise.
- Stockage des données : les données sont conservées dans des environnements cloud, on-premise ou hybrides, selon les besoins en matière de performance, de coût et d’accessibilité. Ce choix conditionnera toute la suite du cycle de vie. 💾
Le stockage des données mérite une véritable réflexion d’architecture :
- Le data lake offre la possibilité de stocker des informations brutes sans structure prédéfinie.
- À l’inverse, un entrepôt de données impose une organisation plus stricte avant intégration.
Selon nous, une petite entreprise a souvent intérêt à privilégier une approche hybride légère plutôt qu’un dispositif trop complexe, difficile à maintenir.
Dans certains cas, il peut également être pertinent de connecter ses environnements de stockage existants à ses outils métiers. Les intégrations de stockage de données cloud proposées par la plateforme HubSpot facilitent justement les échanges avec certains entrepôts de données externes afin de rendre les informations plus accessibles aux équipes.
Les 3 dernières étapes : qualité, gouvernance des données, et fin du cycle de vie
C’est l’ensemble des paramètres (qualité, gouvernance, exploitation et suppression des données) qui détermine la fiabilité des informations produites.
La pertinence d’un reporting, d’une analyse ou même d’un modèle d’IA dépend entièrement de la qualité des données injectées.
Parallèlement, la suppression est souvent reléguée au second plan. Pourtant, conserver des données au-delà de leur durée autorisée expose l’entreprise à un risque réglementaire réel, notamment au regard du RGPD. ☝️🤓
Tableau récapitulatif des 6 étapes de traitement des données
| Étape | Objectif principal | Risque si négligée |
| Collecte et ingestion | Récupérer les données depuis plusieurs sources de données | Données incomplètes ou dupliquées |
| Intégration et organisation | Standardiser et structurer l’information | Incohérences entre les systèmes |
| Stockage | Assurer le stockage des données de façon performante et accessible | Perte de données ou coûts excessifs |
| Qualité et gouvernance | Maintenir la qualité et la gouvernance des données | Décisions erronées, pertes financières |
| Utilisation et analyse | Transformer les données en information exploitable | Manque à gagner, retard concurrentiel |
| Conservation et suppression | Maîtriser le cycle de vie des données jusqu’à leur suppression | Sanctions RGPD, risques juridiques |
Quels sont les enjeux du data management pour une entreprise ?
Mal gérées, les données coûtent immédiatement cher : erreurs de reporting, décisions mal orientées, perte d’opportunités commerciales ou non-conformité réglementaire. 🫤
Ce qui fait véritablement la différence, ce n’est pas le volume d’informations stockées, mais la rigueur avec laquelle elles sont collectées, organisées et exploitées.
Décision, performance et avantage concurrentiel
Une gestion de données solide donne aux dirigeants une information précise, cohérente et à jour. En pratique, une décision prise sur des bases de données fiables réduit le risque d’erreur et accélère l’exécution. 👌
Avantages d’un data management efficace pour une entreprise :
- Prise de décision rapide : des tableaux de bord alimentés par des données fiables permettent d’arbitrer sans attendre. ⚡
- Optimisation opérationnelle : une analyse structurée permet d’obtenir des gains de productivité, une baisse des coûts et une meilleure allocation des ressources.
- Pilotage par les KPI : des indicateurs à jour permettent de suivre l’activité et de repérer les signaux faibles avant qu’ils ne deviennent problématiques. 📊
La gestion des données aide les TPE et les PME à structurer leurs informations, à fiabiliser leurs reportings et à mieux piloter leurs actions marketing.
Quid de l’IA dans le data management ?
L’intelligence artificielle peut accélérer ce travail, mais elle ne corrigera pas des données de faible qualité. Si la collecte en amont est instable, les résultats le seront aussi. 🤖
Conformité RGPD et gestion des risques
La conformité des données ne sert pas uniquement à éviter une sanction.
La protection des informations personnelles est devenue un critère de confiance, au même titre que la qualité de service ou le respect des délais. 🔒
D’ailleurs, une entreprise incapable de prouver sa conformité peut potentiellement perdre un client, un appel d’offres ou un partenariat. ☹️
La confidentialité, le contrôle des accès et la gestion des durées de conservation doivent donc relever d’un cadre continu.
Un système de gestion des données bien défini simplifie les audits de conformité et limite les prises de risques. Adopter une méthode claire vous permet donc de rester serein en toutes circonstances. 🧘
Impact sur la croissance et le marketing
Les données clients bien structurées améliorent directement l’efficacité marketing.
La segmentation, le ciblage publicitaire et la personnalisation des parcours reposent tous sur des bases de données propres. Dès qu’un fichier client se dégrade, les campagnes deviennent plus coûteuses et moins performantes, et le suivi des prospects ne peut plus être correctement assuré.
A l’inverse, une meilleure qualité des données peut faire progresser significativement les conversions, simplement parce que les messages atteignent les bonnes personnes, au bon moment (amélioration du lead nurturing). 🎯
Les entreprises qui utilisent l’outil en ligne HubSpot peuvent notamment s’appuyer sur son CRM unifié pour centraliser les données issues des équipes marketing, commerciales et du service client. Cette vision globale facilite la segmentation des audiences, l’identification des opportunités et la personnalisation des campagnes automatisées, sans multiplier les exports ni les manipulations manuelles.
D’ailleurs…
96 % des utilisateurs de la plateforme HubSpot déclarent que la personnalisation de l’expérience client a favorisé la croissance de leurs ventes. 📈
Bonnes pratiques pour une gestion de données efficace
Généralement, dans la gestion de données, le problème concerne moins les outils que la méthode.
Dans les faits, une entreprise obtient souvent de meilleurs résultats avec des règles claires, des rôles définis et une automatisation progressive qu’avec un logiciel coûteux mal paramétré. ⚙️
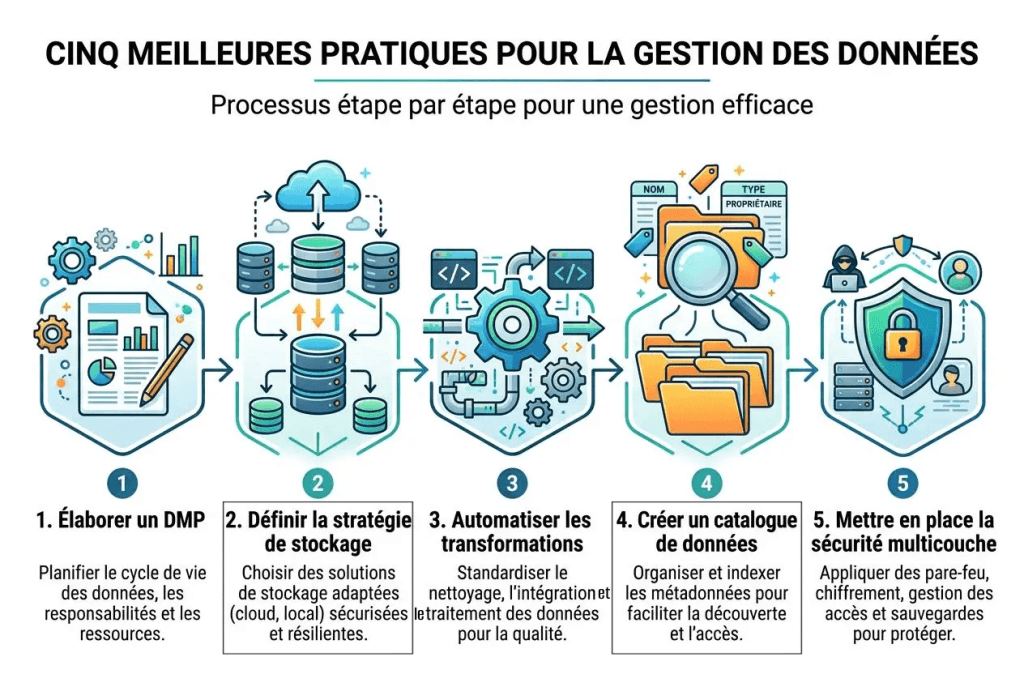
Créer un plan de gestion des données réellement exploitable
Les bonnes pratiques en gestion de données commencent par un document de référence : le Data Management Plan. ✍️📄
Ce cadre précise notamment :
- Qui est le responsable de chaque jeu de données,
- Quels formats sont utilisés,
- Comment nommer les fichiers et les champs,
- Quels accès sont autorisés
- Et comment les sauvegardes sont organisées.
Sans ces précisions, le moindre congé ou départ d’un collaborateur peut entraîner une perte d’information ou des difficultés de transmission.
Éléments essentiels à intégrer à votre programme de gestion des données :
- Identification des responsables : chaque base de données doit disposer d’un référent chargé de la qualité, de la mise à jour et de la conformité.
- Règles de nommage : une convention cohérente facilite la recherche, limite les erreurs et simplifie l’intégration entre systèmes.
- Sauvegardes : il est indispensable de documenter leur fréquence, leur emplacement et les procédures de restauration. Attention, une sauvegarde non testée n’est pas fiable. ⚠️
Par ailleurs, lorsqu’une entreprise utilise plusieurs outils, centraliser les données au sein d’une plateforme unique peut considérablement simplifier leur gouvernance. Or, le CRM de HubSpot répond précisément à cette logique en regroupant les informations clients dans un environnement partagé par les équipes marketing, commerciales et d’assistance.
Automatisation, IA et catalogues pour mieux gérer les données
Quand les volumes de données augmentent, une gestion entièrement manuelle tend à multiplier les erreurs et à mobiliser les équipes sur des tâches répétitives à faible valeur ajoutée. 😩
Pour accompagner la croissance d’une activité il est recommandé d’adopter des pratiques plus avancées comme l’automatisation de certains traitements ou la détection proactive des anomalies.
Les entreprises peuvent notamment s’appuyer sur des outils capables de :
- Standardiser automatiquement certaines données,
- Synchroniser plusieurs applications,
- Enrichir des informations existantes,
- Signaler des incohérences,
- Déclencher des actions selon des règles prédéfinies.
Dans cet esprit, l’outil digital HubSpot propose des fonctionnalités d’automatisation programmable, permettant de développer des automatisations personnalisées adaptées aux processus métiers spécifiques de l’entreprise. Cela permet de réduire les interventions manuelles tout en renforçant la fiabilité des opérations.
Toujours sur la plateforme HubSpot, le Data Studio offre la possibilité de préparer et transformer les données grâce à une interface visuelle proche d’un tableur. Les équipes peuvent ainsi manipuler les informations plus facilement. 👍
Si votre volume d’informations non répertoriées devient important, il peut également être judicieux de mettre en place une couche de découverte permettant d’identifier les ressources disponibles et de mieux comprendre leur contenu. Cette démarche favorise l’autonomie des équipes et limite les pertes de temps liées à la recherche d’information.
Sécurité des données, accès et gouvernance
La sécurité des données repose sur plusieurs niveaux complémentaires :
- Le chiffrement,
- Le contrôle d’accès par rôle,
- La journalisation
- Et la détection des anomalies.
Il est important de définir dès le départ qui peut consulter, modifier ou partager l’information, dans quelles conditions, et avec quel consentement de la part des utilisateurs.
Dans les faits…
Les incidents de sécurité proviennent davantage d’erreurs internes ou d’autorisations mal configurées que d’attaques sophistiquées menées depuis l’extérieur.
Or, une entreprise qui formalise la propriété des données et les droits d’accès en amont réduit considérablement les risques d’accès non autorisés. 😌
Architectures et stratégie de data management
La stratégie de data management détermine la façon dont une entreprise va gérer ses données, les faire circuler entre équipes et les rendre exploitables pour l’analyse, l’automatisation ou l’IA.
Data lake, entrepôt de données et data fabric : qu’est-ce qui les distingue ?
Le choix entre ces modèles aura des conséquences directes sur les coûts, la performance et la capacité à faire évoluer les usages : 🔎
- Data warehouse (entrepôt de données) : il centralise des données structurées selon un schéma défini dès leur ingestion. Cette approche est particulièrement adaptée lorsque les besoins de reporting, de pilotage et d’analyse métier sont clairement identifiés et relativement stables.
- Data lake : il conserve les données brutes, qu’elles soient structurées ou non, avec un schéma appliqué au moment de leur exploitation. Cette architecture convient davantage aux environnements de big data, aux projets exploratoires ou aux entreprises amenées à croiser des formats très variés.
- Data fabric : il relie plusieurs systèmes, sans imposer une centralisation complète sur une seule plateforme. Cette approche devient pertinente quand les bases de données, les applications métiers et les environnements cloud sont dispersés.
Pour une PME ou une structure en croissance, un entrepôt de données reste souvent le point de départ le plus simple à administrer.
Cependant, à mesure que les outils se multiplient, l’enjeu ne réside plus uniquement dans le stockage, mais dans la capacité à faire circuler l’information de façon fluide.
C’est précisément pour répondre à ce besoin que certaines plateformes proposent des fonctionnalités de synchronisation native. C’est notamment le cas du logiciel Data Sync de HubSpot.
Des utilisateurs satisfaits…
Pas moins de 89 % des clients HubSpot déclarent mieux centraliser leurs données et disposer d’une vision plus fiable et cohérente de leur activité. 👀
ETL, MDM et intégration des données pour éviter les doublons
Une stratégie de données solide repose sur des mécanismes d’intégration des données précis :
- L’ETL (Extract, Transform, Load) reste une approche éprouvée pour alimenter un entrepôt de données : les informations sont d’abord extraites, puis transformées avant d’être chargées dans leur environnement cible.
- L’ELT (Extract, Load, Transform) s’impose davantage dans les architectures cloud, où les capacités de calcul permettent d’effectuer les transformations après le chargement des données.
- Enfin, lorsque des besoins de synchronisation quasi instantanée apparaissent, les entreprises privilégient souvent des approches reposant sur la CDC (Change Data Capture).
CDC, définition
La capture des données modifiées (CDC) est une technique permettant d’identifier et de transférer uniquement les mises à jour d’un système source vers des outils tiers, tels que des entrepôts de données, des applications en temps réel ou des solutions de pilotage.
Dans ce cas, l’intérêt est double :
- Limiter les volumes transférés,
- Garantir que chaque système exploite des informations actualisées.
MDM : la clé pour éviter les incohérences
Le véritable défi apparaît lorsqu’une même entité existe sous plusieurs formes.
Un client peut, par exemple, être enregistré avec des orthographes différentes selon les logiciels utilisés par les équipes commerciales, marketing ou administratives.
Sans règles communes, ces écarts fragilisent rapidement les analyses et compliquent les prises de décision.
C’est précisément là qu’intervient le MDM (Master Data Management).
La gestion des données de référence consiste à centraliser et à fiabiliser les objets clés de l’entreprise (clients, fournisseurs, produits ou partenaires) afin de garantir la cohérence des analyses croisées.
Ce dispositif devient indispensable dès lors qu’une organisation s’appuie sur plusieurs sources d’information.
D’ailleurs, la notion de source unique de vérité, mise en avant par la plateforme web HubSpot au sein de son Smart CRM, répond à cette même ambition : permettre aux équipes de travailler à partir d’informations homogènes et fiables, sans intervention manuelle.
Une efficacité reconnue…
83 % des utilisateurs déclarent que HubSpot CRM leur permet d’unifier l’ensemble de leurs données, de façon efficiente.
Comment construire une stratégie de data management durable ?
Une stratégie de data management fixe :
- Les responsabilités,
- Les règles communes,
- Les priorités d’évolution,
- Les conditions dans lesquelles les équipes produisent, partagent et contrôlent les données.
Selon nous, une stratégie efficace fonctionne mieux quand elle n’est pas enfermée dans la technologie. Il est essentiel de traiter la donnée comme un actif transversal, avec des responsabilités distribuées entre les différents métiers, les équipes techniques et les responsables de la conformité.
Le data mesh pousse cette logique plus loin. Les équipes métier deviennent alors responsables des jeux de données qu’elles produisent, de leur qualité et de leur disponibilité, comme ce serait le cas pour un produit.
Foire aux questions sur la gestion des données / data management
Qu’est-ce que le data management en entreprise ?
La gestion de données en entreprise regroupe les méthodes, les outils et les règles qui servent à collecter, stocker, organiser, sécuriser et exploiter l’information pendant tout son cycle de vie.
La fiabilité constitue le critère central : des bases de données bien structurées, des fiches clients exploitables et une information accessible au bon moment.
En pratique, cela englobe aussi bien les documents internes, l’intégration des différentes informations issues de plusieurs outils et la conformité aux obligations réglementaires.
Quels sont les principaux processus de la gestion de données ?
Une gestion de données solide se structure en 3 axes principaux :
- La collecte,
- L’intégration des données
- Et leur exploitation.
S’y ajoute un point décisif, souvent sous-estimé : la gouvernance, qui fixe les règles de qualité, de sécurité, de responsabilité et de conformité applicables aux données, dans l’entreprise.
Sans ce cadre, les bases de données s’accumulent, mais l’information demeure difficile à exploiter. 🤷
Le recours à des outils de synchronisation ou de contrôle qualité comme le logiciel Data Hub de la solution digitale HubSpot peut également faciliter ces processus, à condition qu’ils s’inscrivent dans une stratégie globale clairement définie.
Quel est le rôle d’un gestionnaire de données ou data manager ?
Le gestionnaire de données, ou data manager, veille à ce que la gestion de données reste cohérente d’un service à l’autre.
Il supervise :
- La qualité des informations,
- La conformité réglementaire,
- Les droits d’accès,
- La disponibilité des données,
- La coordination entre les équipes métier et les équipes techniques.
Selon nous, ce rôle devient indispensable dès qu’une entreprise s’appuie sur plusieurs outils, plusieurs sources de données clients ou plusieurs bases de données à maintenir dans la durée.



